コンピュータはことばを理解できる?
コンピュータと人間が自然な会話ができるようになるとしたらどんなことができるようになるでしょうか?2022年11月に公開されたChatGPTというAIシステムはその夢を現実に近づけました。ChatGPTは自然言語処理(Natural Language Processing, NLP)という技術を使っています。自然言語処理とは人間が使う言葉(自然言語)をコンピュータで処理する技術のことです。このブログ記事では自然言語処理の仕組みについて何回かに分けて解説していきたいと思います。
前回の記事
自然言語処理の常識を覆した会話型生成AIへの道のり[3] “単語が織り成す多次元の世界”
![自然言語処理の常識を覆した会話型生成AIへの道のり[4-最終回] “文脈が開く無限の世界”](/assets/img/img_blog79_01.jpg)
単語の続き
分布仮説(Distributional Semantics)
分布仮説(Distributional Semantics、分布意味論とも)[注釈1]は、1957年にJ. R. Firthによって広められた「単語の使われた文脈の類似性と単語の意味の類似性には相関がある」という仮説で、統計的意味論の基礎となる考えです。
You shall know a word by the company it keeps (言葉の性質は、そのつながりを見ればわかる) J. R. Firth
分布仮説を簡単にイメージするために以下の例を考えてみましょう。例えば「dogs are cute.」と「cats are cute.」という2つの文を考えてみると「dogs」と「cats」は同じような文脈で使われているため、この2つの単語は分布仮説に基づくと強い相関性がある(≒類似性がある)と見なせます。
もう1つ例を考えてみましょう。ある文章に「りんご」という単語が出現したとします。このとき「りんご」の意味はその文章の中でどのような単語と共起しているかによって決まります。例えば「りんご」の近くに「赤い」という単語があれば「りんご」は赤色の果物であることがわかります。しかし「りんご」の近くに「iPhone」という単語があれば「りんご」はApple社のロゴであることがわかります。つまり「りんご」の意味はその単語が出現する文脈によって変化するということです。
このように単語や文の意味はそれらが出現する分布によって決まるというのが分布仮説の核心です。分布仮説を用いれば自然言語を数学的なモデルで扱えるようになります。分布仮説は、word2vecを始めとする近年の自然言語処理の応用や発展に大きく貢献しています。そしてもちろんニューラル機械翻訳もその恩恵を受けている重要な考え方です。
word2vec
word2vec[注釈2]は「単語の意味はその周辺の単語によって決まる」という分布仮説の考え方に基づき、ニューラルネットワークを用いて大量のテキストデータから単語の意味的・文法的な特徴を捉えた単語ベクトルを学習します。word2vecには、周囲の単語から目的の単語を予測することに焦点を当てたContinuous Bag-of-Words(CBOW)と、周囲の単語から目的の単語を予測することに焦点を当てたSkip-gramという2つのアーキテクチャがあります。下記のword2vec.pyは、corpus.txtからword2vecで単語ベクトルを学習し、似ている単語を出力し、テキストベクトルのコサイン類似度を計算するするPythonスクリプトです。スクリプト実行の前にターミナルでpip install gensimを実行してトピックモデリングライブラリgensim[注釈3]のインストールが必要です。
''' corpusからword2vecで単語ベクトルを学習し、似ている単語のリストを出力し、 テキストベクトルのコサイン類似度を計算するPythonスクリプト word2vec.py スクリプト実行の前にpip install gensimの実行が必要です ''' import nagisa from multiprocessing import Pool from gensim.models import Word2Vec from sklearn.metrics.pairwise import cosine_similarity def word_segmentaion(text): return nagisa.tagging(text).words corpus_filepath = './corpus.txt' with Pool() as p: corpus = p.map(func=word_segmentaion, iterable=open(corpus_filepath)) model = Word2Vec(sentences=corpus, vector_size=100, min_count=1, window=5) def word_vector(text): segmented = word_segmentaion(text) vectors = [model.wv[word] for word in segmented if word in model.wv.index_to_key] words = ['猫', 'ネコ', '猫ちゃん', '熊'] for target_word in words: similar_words = [] for w in model.wv.index_to_key if w==target_word: continue similar_words.append((w, model.wv.similarity(target_word, w))) sorted_similar_words = sorted(similar_words, reverse=True, key=lambda x: x[1]) print(target_word, sorted_similar_words[:5]) print() texts = [ '猫が魚を食べた', 'ネコが魚を食べた', '猫ちゃんが魚を食べた', '熊が魚を食べた', '魚が猫を食べた', ] segmented_texts = [' '.join(nagisa.tagging(x).words) for x in texts] text_vectors = [word_vector(x) for x in texts] print(cosine_similarity(text_vectors))
スクリプトを実行した結果をまとめたのが次の表です。この結果を見る限り、「猫」と「ネコ」と「猫ちゃん」が同義語であることは獲得できたように見えます。また、今回のcorpus.txtには熊に関する記述が極めて少なく「熊」に似ている単語の列挙は難しいと思っていたのですが、それでもそれなりに動物だけを列挙してきたところを見ると、同じ動物であるということは理解できたようです。
| 猫 | 類似度 | ネコ | 類似度 | 猫ちゃん | 類似度 | 熊 | 類似度 | |||
|---|---|---|---|---|---|---|---|---|---|---|
| ネコ | 0.7970614 | 猫 | 0.7970614 | 猫 | 0.90984255 | 狐 | 0.8589551 | |||
| 野良猫 | 0.75848712 | イヌ | 0.74347705 | 猫ちゃん | 0.8127355 | 狼 | 0.853503 | |||
| 子犬 | 0.70092412 | 野良猫 | 0.69092274 | 黒猫 | 0.80792636 | 猿 | 0.8468948 | |||
| 黒猫 | 0.69553757 | ネズミ | 0.6674601 | ねこ | 0.7674455 | 鹿 | 0.84284717 | |||
| 子猫 | 0.67812985 | 子犬 | 0.6395994 | 子猫 | 0.75560635 | 羊 | 0.81318915 |
word2vecは単語ベクトルを得るためのものですが、テキストに含まれる全ての単語の平均単語ベクトルを計算しそれをテキストベクトルとみなすこともできます。そのようにしてテキストのペアのコサイン類似度を計算した結果が次の表です。
| テキストのペア | コサイン類似度 |
|---|---|
| 猫が魚を食べた ネコが魚を食べた |
0.981247 |
| 猫が魚を食べた 猫ちゃんが魚を食べた |
0.97745615 |
| 猫が魚を食べた 熊が魚を食べた |
0.9598155 |
| 猫が魚を食べた 魚が猫を食べた |
1.0 |
この結果から「猫」と「ネコ」と「猫ちゃん」が同義語であることはうまく認識されたように見えます。そして「猫」と「熊」が同義語ではないこともはっきりと認識されたように見えます。しかしながらまだ4つ目のテキストペアについては意図した類似度が出ていません。というのも、テキストベクトルをテキストを構成する単語の単語ベクトルの平均という形で表しているからです。
fastText
他にも単語ベクトルを試してみることにします。fastText[注釈4]は旧Facebook AI Research (FAIR)ラボで開発されました。この手法の面白いところは、単語だけでなくサブワード(文字以上単語以下の単位)の両方を考慮するため、コーパスに現れなかった単語でもそれなりに処理できてしまうというところです。word2vecはコーパスに現れなかった単語を処理することはできません。またfastTextでは「ヴェネチア」と「ヴェネツィア」のような表記ゆれや「押さえる」「押える」といった送り仮名の違いに対して単語の部分一致が類似度に反映されるため、これらの単語間の類似度はword2vecよりも高く計算することが可能です。下記のfasttext.pyは、corpus.txtからfastTextで単語ベクトルを学習し、似ている単語を出力し、テキストベクトルのコサイン類似度を計算するPythonスクリプトです。このスクリプトではcorpus.txtが数百GBでも扱えるようにイテレータやmmapを使って省メモリ高効率で処理するように変更を加えてみました。
''' fastTextで単語ベクトルを学習し、似ている単語のリストを出力し、 テキストベクトルのコサイン類似度を計算するPythonスクリプト fasttext.py ''' import mmap from pathlib import Path import nagisa from multiprocessing import Pool import os from gensim.models import FastText # https://stackoverflow.com/questions/845058/how-to-get-line-count-of-a-large-file-cheaply-in-python def count_nb_lines_mmap(file: Path) -> int: """Count the number of lines in a file""" with open(file, mode="rb") as f: mm = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ) nb_lines = 0 while mm.readline(): nb_lines += 1 mm.close() return nb_lines def word_segmentaion(args): i, text = args[0], args[1] filepath = f'temp_{i}.txt' with open(filepath, 'w') as f: segments = nagisa.tagging(text).words output_text = ' '.join(segments) f.write(output_text) def file_reader(filepath): with open(filepath) as f: for i, text in enumerate(f): yield i, text raw_filepath = './corpus.txt' corpus_filepath = './corpus.segmented.txt' model_filepath = './fasttext.model' # 単語分割処理を平行して走らせます。 with Pool() as p: p.map(func=word_segmentaion, iterable=file_reader(raw_filepath)) # 単語分割結果を1つのテキストファイルにまとめます。 n_lines = count_nb_lines_mmap(raw_filepath) with open(corpus_filepath, 'w') as out: for i in range(n_lines): with open(f'temp_{i}.txt') as inp: out.write(inp.read()) out.write('\n') os.remove(f'temp_{i}.txt') model = FastText(vector_size=100, window=7, min_count=1) model.build_vocab(corpus_file=corpus_filepath) total_words = model.corpus_total_words model.train(corpus_file=corpus_filepath, total_words=total_words, epochs=10) model.save(model_filepath) words = ['猫', 'ネコ', '猫ちゃん', '熊'] for target_word in words: similar_words = [(x, model.wv.similarity(target_word, x)) for x in model.wv.index_to_key] sorted_similar_words = sorted(similar_words, reverse=True, key=lambda x: x[1]) print(target_word, [x for x in sorted_similar_words[:6] if x[0]!=target_word]) print() def word_vector(text): segmented = nagisa.tagging(text).words vectors = [model.wv[word] for word in segmented if word in model.wv.index_to_key] return np.mean(vectors, axis=0) texts = [ '猫が魚を食べた', 'ネコが魚を食べた', '猫ちゃんが魚を食べた', '熊が魚を食べた', '魚が猫を食べた', ] segmented_texts = [' '.join(nagisa.tagging(x).words) for x in texts] text_vectors = [word_vector(x) for x in texts] print(cosine_similarity(text_vectors))
スクリプトを実行した結果をまとめたのが次の表です(なお上位5位に狙った単語が出てこなかったので、個別に計算して入れた単語の類似度には単語の後ろに*を付けています)。word2vecとはまた違った結果になりました。例えば「猫」の結果を見ると、上位は全て猫関連の単語であり、word2vecよりもうまく処理されていることが分かります。類似度が0.74以上かそうでないかで同義語であるかどうかを判定できそうです。また、「ネコ」と「猫ちゃん」の結果ではその単語の一部を含む語が上位に現れているようです。奇妙な単語なのでコーパスまで戻ってこれらの単語の使われ方を調べたところ、これらの語は単語分割の失敗で生まれてしまった単語であることが分かりました。このように、単語ベースでの処理は単語分割での失敗が後続の処理に影響を当たえてしまうので注意が必要です。そして「熊」に対して「猫」の類似度は0.45であり同義語でないことを認識できたように見えます。
| 猫 | 類似度 | ネコ | 類似度 | 猫ちゃん | 類似度 | 熊 | 類似度 | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 猫ちゃん* | 0.9641365 | ネコ耳ネコ | 0.94996756 | かちゃん | 0.99812585 | 狐 | 0.8685529 | |||
| 飼いネコ | 0.7725697 | ネコ・ネコ | 0.9424523 | みかちゃん | 0.99421465 | 狼 | 0.83288974 | |||
| 子ネコ | 0.7619973 | ネコネコ | 0.94029397 | くまちゃん | 0.99404955 | 鹿 | 0.8284312 | |||
| 雌ネコ | 0.7538799 | ネコ目ネコ | 0.9258821 | ぼうちゃん | 0.99330246 | 猿 | 0.81124276 | |||
| ギコネコ | 0.75320184 | 綱ネコ | 0.92509633 | ちゃん | 0.99233043 | 牛 | 0.80265945 | |||
| バケネコ | 0.75208867 | 猫ちゃん* | 0.7495326 | 猫* | 0.9641365 | 猫* | 0.45018706 | |||
| ネコ* | 0.74910605 | 猫* | 0.74910605 | ネコ* | 0.74910605 | 魚* | 0.23092163 |
これまでと同様に4つのテキストペアについてのコサイン類似度を計算した結果は次の表のようになりました。やはり4つ目のテキストのペアの類似度は、テキストベクトルを単語ベクトルベースで処理する弊害で期待通りの類似度が出ていません。
| テキストのペア | コサイン類似度 |
|---|---|
| 猫が魚を食べた ネコが魚を食べた |
0.9687905 |
| 猫が魚を食べた 猫ちゃんが魚を食べた |
0.9918658 |
| 猫が魚を食べた 熊が魚を食べた |
0.9436523 |
| 猫が魚を食べた 魚が猫を食べた |
1.0 |
また、fastTextによる単語ベクトルがどのように単語間の関係を捉えているのかを可視化するために、t-SNE[注釈5]で3次元空間に落とし込みplotly[注釈6]で描画しました。全部の単語を描画すると見辛いので「猫」「熊」「船」を含む単語のみを描画しています。猫のクラスタ、船のクラスタ、地名のクラスタなどが確認できると思います。再生ボタンを押してアニメーション表示したりマウスで拡大縮小回転できるので色々な角度から確認してみてください。
Sentence-BERT
さて、これまでは単語埋め込みベクトル[注釈7]からテキストベクトル(≒文ベクトル)を作成していましたが、初めから文や段落等の長いテキストを低次元のベクトルに変換する、つまり長いテキストをベクトルに埋め込む方法があります。例えばELMo[注釈8]やBERT[注釈9]等は文埋め込みベクトルとして有名です。BERTモデルの訓練には数億語以上のコーパスが必要になりますが、これまでの実験で使ったコーパスは1,000万語程度の規模でBERTモデルを訓練するには小規模なので、ここではHugging Face Hub[注釈10]で公開されているsentence-transformers/xlm-r-100langs-bert-base-nli-mean-tokens[注釈11]というモデル(BERTを改良したRoBERTa[注釈12]を多言語化したXLM-RoBERTa[注釈13]を事前訓練済みモデルとして選びSiamese Network[注釈14]でファインチューニングしたモデル)を使い実験を進めていきたいと思います。
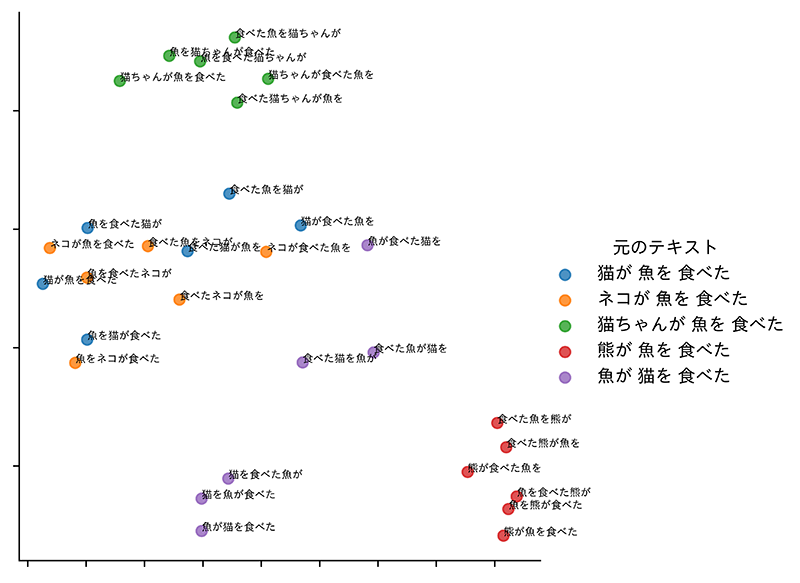
文埋め込みベクトルがどの程度語順を考慮できるものなのかを調べるために下記のスクリプトを作りました。このスクリプトはこれまでのサンプルとして使った5つの文を文節化し全文節の順列を列挙してできた文の文埋め込みベクトルを計算後、t-SNEで2次元空間に落とし込み、seaborn[注釈15]で描画するPythonスクリプトです。スクリプト実行の前にpip install -U sentence-transformersを実行してSentenceTransformersライブラリとpip install seabornを実行してデータ可視化ライブラリseabornのインストールが必要です。
''' 文埋め込みベクトルを可視化するPythonスクリプト visualization.py ''' from itertools import permutations import numpy as np from sentence_transformers import SentenceTransformer from sklearn.manifold import TSNE import pandas as pd import seaborn as sns import matplotlib.pyplot as plt texts = [ '猫が 魚を 食べた', 'ネコが 魚を 食べた', '猫ちゃんが 魚を 食べた', '熊が 魚を 食べた', '魚が 猫を 食べた', ] patterns = [] patterns.extend([''.join(p) for text in texts for p in permutations(text.split())]) model_id = 'sentence-transformers/xlm-r-100langs-bert-base-nli-mean-tokens' model = SentenceTransformer(model_id) text_vectors = np.array([model.encode(pattern) for pattern in patterns]) tsne_model = TSNE(n_components=2, perplexity=14, random_state=0, verbose=0) np.set_printoptions(suppress=True) tsne_model.fit_transform(text_vectors) text_vectors_tsne = pd.DataFrame(tsne_model.embedding_[:, 0], columns=['x']) text_vectors_tsne['y'] = pd.DataFrame(tsne_model.embedding_[:, 1]) text_vectors_tsne['Text'] = list(patterns) text_vectors_tsne['元のテキスト'] = [texts[i] for i in range(5) for _ in range(6)] g = sns.lmplot(data=text_vectors_tsne, x='x', y='y', hue='元のテキスト', fit_reg=False) g.set(xticklabels=[], xlabel=None, yticklabels=[], ylabel=None) for ax in g.axes.flat: x_data = text_vectors_tsne['x'] y_data = text_vectors_tsne['y'] labels = text_vectors_tsne['Text'] for x, y, label in zip(x_data, y_data, labels): ax.text(x, y, label, fontsize=6)
実際に得られた結果を次に示します。期待していた結果は、グラフ上にプロットされた点が元々の文に対応する5つのクラスタに分割されるか、同義語を考慮して3つの文が1つのクラスタに集約されたことでそれ以外が3つのクラスタに分割されることです。しかし実際には「熊が魚を食べた」は明確なクラスタを構成し、「猫が魚を食べた」と「ネコが魚を食べた」は概ね1つのクラスタになりましたが、「猫ちゃんが魚を食べた」は微妙に離れた1つのクラスタを構成することになりました。そして、これまで問題になっていた「魚が猫を食べた」は、6つのバリエーションのうち3つは明確に他の文と離れて1つのクラスタを構成して「猫が魚を食べた」と意味が異なることを認識できたようですが、残りの3つはそうではありませんでした。文節の順序を変えれば係り受けが変わる可能性が生じるので1つの文から生成したバリエーションが同じ1つのクラスタに間違いなく属しなければならないということはなくなるため、これは妥当な結果とも言えます。
GPT-4(対話型生成AI)
最後にGPT-4[注釈16]で実験をしました。GPT-4はOpenAIが開発した対話型生成AIで、GPT-4のアーキテクチャは詳細に公開されていませんがこれまでのGPTシリーズは入力テキストを一旦埋め込みベクトルに変換しその後何十層ものニューラルネットワークを経てテキストを生成する仕組みになっています。このGPT-4にこれまでの4つのテキストペアの意味的類似度を推定してもらいました。以下がその結果です。

これまでの苦労が徒労であったかと思わせるような、こちらの意図を理解した見事な回答が返ってきました。類似度の値は主観的ではありますが妥当に見えますし、その類似度を付けた理由の説明も尤もらしく聞こえます。このように、対話型生成AIはこれまでの自然言語処理技術を時代遅れにさせるような強烈な発明であったことがご理解いただけたかと思います。勿論、本当の意味で理解しているのかといった批判[注釈17]や事実に基づかない情報を生成するハルシネーションと呼ばれる現象[注釈18]や記号的推論力や論理的推論力に関する議論[注釈19][注釈20]などがあり未完成な技術であることは事実です。しかし短期間にここまで進歩してきたことを鑑みると、今後はAIに使われる人間になるのではなくAIと上手に付き合える人間になることが必要になってくると考えられます。対話型生成AIはそのための一つの手段です。私たちはAIと共存する時代に来ており対話型生成AIはその時代をより豊かにする可能性を秘めていると言えます。
おわりに
サン・フレアではお客様のビジネス コンテンツの品質と効率を向上させるために、最新の生成系 AI の活用を模索しています
弊社の翻訳エキスパートがお客様のニーズに合わせて、この革新的なテクノロジーを最適に利用する方法をご提案いたします。 生成系人工知能(GenAI)と大規模言語モデル(LLM)は、コンピューター科学者たちが長年研究してきた分野ですが、2022 年に米国のテクノロジー企業 OpenAI が開発した LLM である ChatGPT が登場したことで、一般の人々の関心も高まりました。このアプリは驚異的な成長を遂げ、ローンチから 2 か月で1 億人超のユーザーを獲得したと報じられています。
生成系 AI テクノロジーは、あらゆる言語でテキストを生成することができるため、私たちの仕事やビジネスに大きな影響を与えます。
ゴールドマン サックスは、このツールによって 2033 年までに世界の国内総生産(GDP)が約 7 兆ドル増加し、生産性が 1.5% 向上すると予測しています。
このテクノロジーがさらに発展し、拡張性が高まることで、ローカリゼーション業界も変革の波に乗ることができます。生成系 AI は既に言語サービスの品質や効率に貢献しています。
サン・フレアは生成系 AI テクノロジーの最新動向に即座に対応し、その可能性を最大限に活かすサービスの提供を目指しています。
出典
- https://en.wikipedia.org/wiki/Distributional_semantics
- https://ja.wikipedia.org/wiki/Word2vec
- https://radimrehurek.com/gensim/
- https://en.wikipedia.org/wiki/FastText
- https://en.wikipedia.org/wiki/T-distributed_stochastic_neighbor_embedding
- https://plotly.com/
- https://ja.wikipedia.org/wiki/単語の埋め込み
- https://en.wikipedia.org/wiki/ELMo
- https://ja.wikipedia.org/wiki/BERT_(言語モデル)
- Hugging Face Hubは、自然言語処理やコンピュータビジョンで使われる機械学習モデルやデータセットを共有したり利用したりできるオンラインプラットフォームです。事前学習済みモデルやデータセットをアップロードして他のユーザーと共有したり、共有されたモデルやデータセットをダウンロードして自分のプロジェクトに利用することができます。https://huggingface.co/docs/hub/index
- https://huggingface.co/sentence-transformers/xlm-r-100langs-bert-base-nli-stsb-mean-tokens
- https://huggingface.co/roberta-large
- https://huggingface.co/xlm-roberta-large
- https://en.wikipedia.org/wiki/Siamese_neural_network
- https://seaborn.pydata.org/
- https://ja.wikipedia.org/wiki/GPT-4
- https://lifearchitect.ai/contrarianism/
- https://fortune.com/2023/03/21/gpt-4-bard-and-more-are-here-but-were-running-low-on-gpus-and-hallucinations-remain/
- https://arxiv.org/abs/2304.03439
- https://wired.jp/article/plaintext-geoffrey-hinton-godfather-of-ai-future-ai/
この記事を書いた人

亀谷 展
株式会社サン・フレアのリサーチサイエンティスト。
深層学習による自然言語処理やビッグデータ処理を担当。