※当文書の内容の複製、転載、生成AIツールへの入力、等は行わないでください。
発行元:株式会社サン・フレア

はじめに
親戚の子に「Nintendoで得意なゲームは何?」と聞かれ「任天堂ねえ…花札かな?」と答える程度にはITの波から取り残されている宇佐山ですが、翻訳業界のIT化は凄まじく、取り残されているわけにはいきません。というわけで今回は「IT難民の初心者チェッカーが翻訳サイト使ってみた」です。手軽に触れられる機械翻訳である翻訳サイトを用いて、どのくらい正確な訳ができるのか、翻訳作業をおこなう際の一助となり得るのか、使う際に落とし穴となり得るポイントは何か、等これから機械翻訳を使ってみようというときに気になることを見ていきたいと思います。それではいってみましょう!
※注意:宇佐山自身は機械翻訳もチェックも初心者ですが、当社には機械翻訳に造詣の深い者も、チェックのエキスパートも勿論きちんと存在します。今回の趣旨はあくまでも初心者の視点で、機械翻訳を使う際の落とし穴や使ってみたらこんなところが予想外だった、というポイントを確認することであり、初心者の手探り実証レポであること、本記事の見解はあくまで初心者の一意見であり当社および当社エキスパートはまた異なる見解を持つ可能性が高いことをご承知おきください。
機械翻訳とは
機械翻訳を試す前に、機械翻訳が何であるか軽くおさらいしましょう。みなさま既にご存じのことと思いますが、機械翻訳とは人ではなく機械、主にコンピュータがおこなう翻訳のことです。翻訳方法は時代に伴い以下のように変化しています。
まず、
- 人間が定義したルールと辞書に基づいてコンピュータが計算処理をし、翻訳文を出力(ルールベース翻訳)する方法が誕生しました。
次いでインターネット上に多量の文章があふれるようになったのに伴い
- 大量の対訳(原文と訳文のペア)データを統計的に解析し、最も頻度の高い訳語を採用→ネット上の膨大な文章というデータの力を活用することで、機械翻訳の質が向上(統計的機械翻訳)し、
更に、2016年
- 人間の脳内で神経細胞がおこなっている情報処理を模したニューラル機械翻訳が登場。極めて自然な翻訳文が作成されるようになりました[1]。
ルールベース機械翻訳、統計的機械翻訳、ニューラル機械翻訳の主なメリットとデメリットは以下の表の通りです。どちらかというと技術開発の際のメリットとデメリットのようですが、翻訳する際に影響が大きいであろう部分を赤い文字にしました。方法によってメリット・デメリットは様々ですが、時代が下るにつれ、流ちょうさに磨きがかかり、また、データが少ない言語、分野にも応用が利くような進歩を遂げていることが分かります。
| メリット | デメリット | |
|---|---|---|
| ルールベース機械翻訳 |
|
|
| 統計的機械翻訳 |
|
|
| ニューラル機械翻訳 |
|
|
[2]より作成。
もっと具体的に知りたい方は
[2]https://mx.wovn.io/blog/0003
や
[3]https://phrase.com/ja/blog/posts/machine-translation/
や
[4]https://www.science.co.jp/nmt/blog/33792/
が参考になるかと思います。
実際に使ってみた
それでは実際に機械翻訳に触れていきましょう。今回は、ニューラル機械翻訳を採用しているMT(Machine Translation:つまり機械翻訳)サービスの中で、主として「DeepL」を見ていくことにします。DeepLを選択した理由は、「できることなら最先端の機械翻訳を使用してみたい」と考えた初心者がおそらく真っ先に手に取るツールの一つであると考えられるためです。
ちなみに当社は、人手翻訳を依頼されている限りにおいて、機械翻訳を下訳として使用すること、すなわち機械翻訳で作成した文を直接加工して最終訳とすること(ポストエディットといいます)は、原則禁止しております。もちろん、辞書やグーグル検索と同じように、より良い表現、適切な訳語を探すために機械翻訳の文を参考にすることは禁止しておりません。「この単語やフレーズ、もっと良い訳語や表現はないかなぁ。一応、機械翻訳の訳も見てみよう」等はOKです。しかし、機械翻訳ツールの出力した訳文に対して、その妥当性や正確性を原文と突き合わせて検証せずに利用することはNGです。解釈が難しい原文や難解な専門用語を機械翻訳がなんとなくうまく訳せているようだからと、言語的、専門的になぜその訳になるのかを自分で確認することなく利用することは絶対にしないでください。また、実案件で使用が許される機械翻訳は、セキュリティが保証された機械翻訳サービスに限定されます。お客様からお預かりした文書のコンテンツを、フリーの機械翻訳サービス等のセキュリティが保証されない翻訳ツールに入力することは厳禁としております。
以上を念頭においた上で、DeepLのサイトに入りましょう。スタート画面はこんな感じです。
「翻訳するにはテキストを入力してください。」のボックスに外国語の文章を入れると自動で何語であるか識別し、対応する日本語文を隣のボックスに提示してくれます。
当社の英語版HP
[5]https://www.sunflare.com/en/service/
からの抜粋を「翻訳するにはテキストを入力してください。」のボックスに投入してみたところ、以下のように
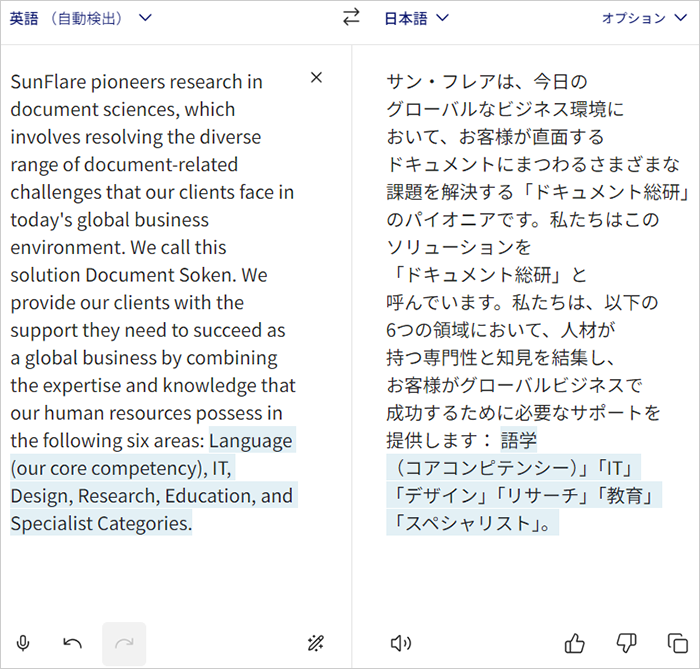
流ちょうな日本語文を返してくれました。
ところで、翻訳の対象分野は、文芸、法務、金融、科学技術、等々、多岐に亘ります。機械翻訳の有用性も対象分野によって異なります。そこで、以下の議論では、有用性が高いと認められている技術系の分野について機械翻訳を試してみます。技術系分野のうち、特許文献からサンプルを抽出して機械翻訳にかけてみます。
始めのほうで述べたように、以降で使用するツールはDeepLです。DeepLについては、利用可能な機械翻訳ツール同士の比較において、技術系翻訳等の産業翻訳の各方面でその有用性が最も優れていると認められており、当社の使用経験からもそのように判断できることから、DeepLの使用を原則としました。
(もちろん、上記の例で示したように、DeepLの優位性は個々の事例においては絶対的ではないことにご留意ください。実務においては、機械翻訳Aも機械翻訳Bも適切に訳しているケース、機械翻訳Aと機械翻訳Bのうち一方が適切に訳しており、他方が適切に訳していないケース、機械翻訳Aも機械翻訳Bも適切に訳していないケース、等々、様々なケースが起こり得ます。訳の適切さ(出来の程度)や不適切さ(不出来の程度)にもグレードがあります。機械翻訳を参考にする際は、複数の機械翻訳文を参照したほうが、有用な情報を得る確率は上がりますが、機械翻訳からは有用な情報が得られない場合もありますので、過信は禁物です。)
特許文献のテキストサンプルとしてまずはWO2019200252を使用しました。
DeepLに入れたらこんな感じになります。
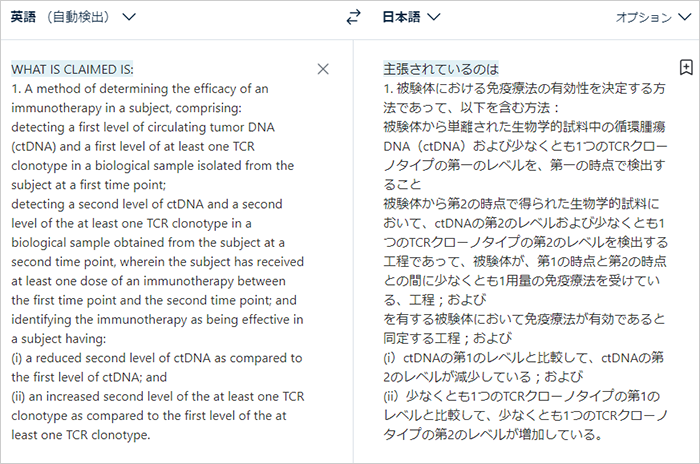
原文は以下の通りです。

DeepLの翻訳は以下の通りです。
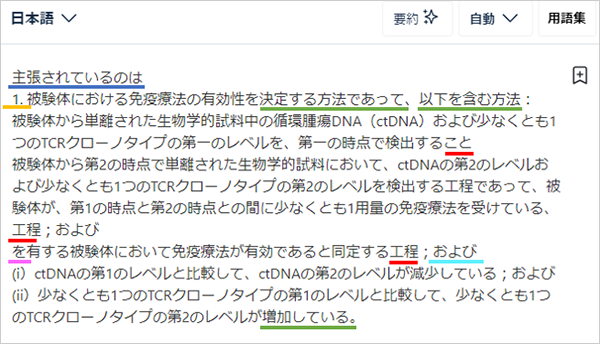
文を見るとまず「【請求項1】はつけてくれない(橙線)」ことと「『決定する方法であって、』って始めてくれるのに、『以下を含む方法』を直後に書いてしまい、『第2のレベルが増加している。』で終わっている(緑線)」ことに気付きます。つまり、書類ごとの特有の様式に則ってはくれない、ということです。確かに、英文だけ見せられてもこれが何の文書に由来するかわからなければ特有の方式で訳すのは難しいですよね、と思いつつも、請求項は英文でも独文でも一つの項は結局一つの名詞なのだから、日本文もそれに呼応して体言止めにしてくれたっていいじゃないか、とも思ったり…。また、英文の特許請求の範囲の冒頭に時々書かれている「WHAT IS CLAIMED IS:」は、日本語では訳さず、日本語の【特許請求の範囲】の冒頭の様式に合わせて訳を作っていくのですが、DeepLでは「主張されているのは(青線)」と訳していることから、こういった様式上訳出しない部位への対応も難しいようです。また、文章に少し踏み入ってみると、「detecting a first...」と「detecting a second...」と「identifying...」という三つの箇条書き部分ですが、ここが「検出すること」、「検出する工程」、「同定する工程」とされてしまい、語尾が統一されていません(赤線)。語尾を「こと」とするべきか「工程」とするべきかは場合によりますが、英文が「~ing」で揃えてきている以上、日本語もどちらかに揃えてほしかったです。これも箇条書きにおける様式、つまり文書の持つ独自の様式に則ってくれない例、と見ることができるでしょう。
それぞれの文書が有する独自の様式に対応した文を作ることが難しい、というDeepLの特徴を一つ確認したところで、今度は内容に踏み込んでみましょう。まず初めに気になるのは箇条書き三つ目の冒頭「を(ピンク線)有する被験体において免疫療法が有効であると同定する工程;および(水色線)」です。「何を」有するのかが書かれずいきなり「を」で始まっているため、日本語として不自然であると言わざるを得ません。また、文末の「;および」は原文に相当する部分がありません。「を有する」に関しては有しているのが何なのかを探して文を組み替えればいいのですが、「;および」については「; and」の位置や個数を正確に見極める注意力が要求されます。また、「書かれてないandが訳されているのであれば書かれていて訳さなければならないandの訳抜けもあるのではなかろうか」と逆の場合や「andがだめだったんだからorもだめなんじゃなかろうか」「and/orもあるよね」「as well asももしかしたらひっかかるかもしれない」と様々な類似箇所についても考慮できたら後々楽になることでしょう。こういった抜けや過剰訳の問題で恐ろしいのは、ある程度の量の文を機械翻訳にかけた後にこのことに気付いたときです。これまで機械翻訳に付した部分の「過剰訳」「訳抜け」「類似」の機能を持つ語でも同様のことが起きている可能性」について、作成した文からすべての箇所を見つけ出し、問題があれば修正することになるわけです。作成してしまった文が多ければ多いほど労力が余計にかかります。機械翻訳がお手軽に正確な翻訳を得られる便利ツールではないことの片鱗が伺えます。
長めの請求項を正確に訳させることは難しいという結果を得ましたが、短いものであればもしかしたら有効に機能するかもしれません。というわけでWO2020131910A1の請求項1です。
原文は以下の通りです。

DeepLによる翻訳文は以下の通りです。
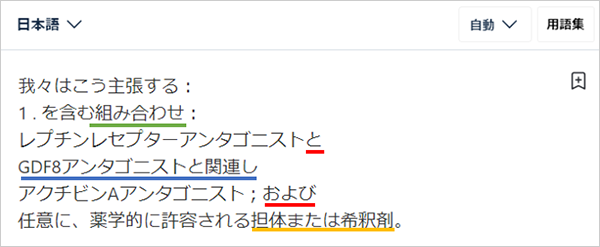
体言で止めてはくれていますが、請求項の主題ではない体言で止められている(橙線)ため、紛らわしいです。主題になる体言部分は今回もやはり請求項の初めに訳出されています(緑線)。改行するとその部分で完結したと見なしてしまうのでしょうか。そうだとしたら原文4行目の「a GDF8 antagonist in association with」が前後との脈絡を感じさせない文「GDF8アンタゴニストと関連し(青線)」とされている謎が解けますが、どうなんでしょうか。また、原文は組み合わせる三つの要素を「A, B and C」と列挙しています。こういった場合、日本語訳としては「AとBとCと」あるいは「A、B、およびC」のどちらかになるのですが、DeepLは「と」と「および」を併用しています(赤線)。「と」を用いるのでしたら「および」は消去して「と」にしなければなりませんし、「および」を使いたいのでしたら始めの「と」は消さなくてはなりません。どちらでもいいですが、どちらかにしなければなりません。
請求項についてさらにもう一つ、請求項中と明細書中の同一箇所についてどのように訳されるのか見ていきましょう。この箇所は、請求項と同一の文章をコピーアンドペーストし、文末などを多少変えればいいだけですので訳す際に楽ができる一方、きちんと同一に訳されているかチェックを必ず入れなければならないところですが、機械翻訳ならば、さすがに同一に訳してくれることでしょう。同じ語が同じ順で並んでいるのですから。というわけでUS10991765B2より抜粋です。ご覧の通り、summaryと請求項1の一部に同一箇所が存在します。黄色の部分が同一箇所です。

同一文を含む部分を拡大すると、明細書部分は

請求項部分は

であり、それぞれsummaryの初めの段落、請求項1の全文(上掲の部分ですね)で区切って機械翻訳にかけると得られる日本語文は以下の通りです。
summary
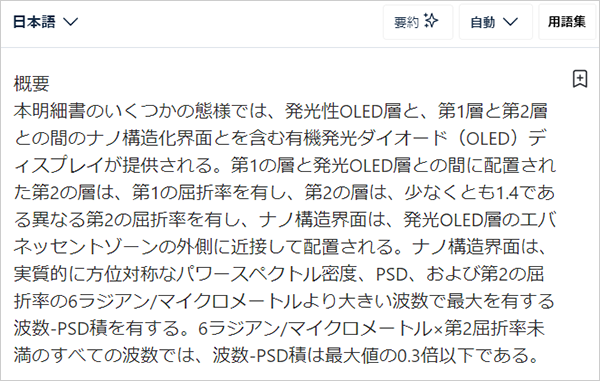
請求項1
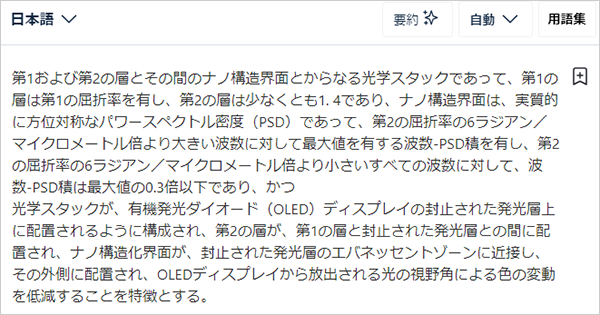
同一箇所の訳は、それぞれ
summary
「6ラジアン/マイクロメートル×第2屈折率未満のすべての波数では、波数-PSD積は最大値の0.3倍以下である。」
請求項1
「第2の屈折率の6ラジアン/マイクロメートル倍より小さいすべての波数に対して、波数-PSD積は最大値の0.3倍以下であり、」
です。
比較をすると
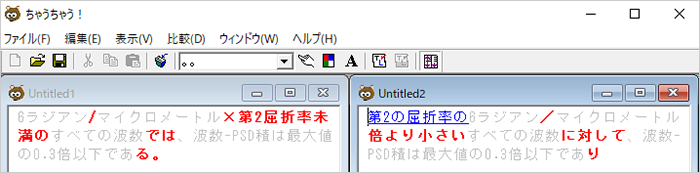
「For all wavenumbers」の「For」の訳語、「less than」の訳出位置および訳語、「6 radians/micrometer times」の「times」の訳語が異なっています。また、スラッシュが半角と全角で揺れています。同一文であっても、前後に異なる文が並んでいる場合は訳出に差異が出る可能性があり、同一に訳されているか気を配る必要があることが分かります。そういえば、ニューラル機械翻訳のデメリットに「翻訳統一が困難」とありましたが、こういうことなんですね。
請求項で楽をしようとして失敗したところで、ほかの楽できそうな部分、すなわち単位付きの数字の羅列や物質名の羅列など、いちいち書くのが面倒な部分を見てみましょう、というわけでUS6110485Aより薬剤名が列挙された箇所を訳させてみました。
原文は以下の通りです。
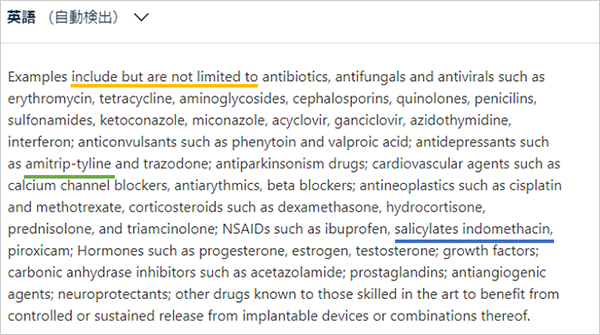
DeepLによる訳文は以下の通りです。
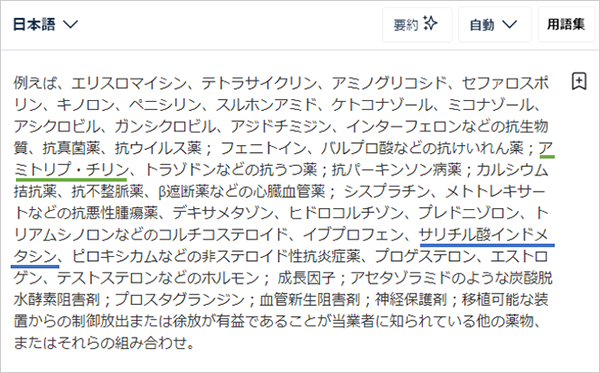
まず、「include but are not limited(橙線)」が翻訳されていません。この部分は「~が挙げられるが、それに限定されない。」等半ば決まり文句と化しているところですので、これはまるっとなくしたりせず訳してほしかったです。薬剤の名称に関しては概ねよいかと思いますが、「アミトリプ・チリン」とされている(緑線)「amitrip-tyline」ですが、ここで切って中黒を入れるのに違和感を覚えました。「アミトリプ」「チリン」という名称の薬にかかわる物質は聞いた記憶がないためです。そのため調べてみましたら「アミトリプチリン(Amitriptyline)」が出てきました。これは行をまたぐときの「-」が中黒と解釈されてしまったものと思われます。ここから、原文で行をまたいでいる箇所は、それに対応する日本語の単語が正しく表記されているか確認しなければならないことが分かります。また、「サリチル酸インドメタシン」、原文では「salicylates indomethacin」(青線)ですが、大学時代の薬理の授業の記憶をあさっても「サリチル酸メチル」「アセチルサリチル酸」「インドメタシン」は出てくるのですが「サリチル酸インドメタシン」は出てきません。というのもここではNSAIDsという抗炎症薬のグループについて述べているのですが、このグループの中の「サリチル酸系」の薬に「サリチル酸メチル」と「アセチルサリチル酸」が、また、NSAIDs内の別グループの「フェニル酢酸系」に「インドメタシン」が属しているためです。別カテゴリーの二つを、名詞そのものも複数形の化合物名と単数形の一般名という併記することがあまりないものなのに一つにまとめて一個の名称のように扱うのは、何かの誤りか革命的技術革新で2カテゴリーをベースに何か新しい薬が開発されたかのどちらかと考えられます。というわけで「salicylates indomethacin」で検索をかけましたがこの名称の単一の物質についての話は出てきませんでした。恐らく「salicylates, indomethacin」と書きたかったのだろうと思われますが、ネットに蓄積した膨大な過去のデータから「この部分は『アミトリプチリン』でこっちは『サリチル酸系、インドメタシン』であろう」と推測して訳出してはくれないことが分かります。結局訳語の正否の最終的な判断は人間がしなければなりません。ただ、これだけの部分を自分で文字を入力せずに、出てきたものをコピーアンドペーストして誤っている部分を修正すれば翻訳を完了できる、というのは文字入力の省力化の観点から非常に魅力的です。では、数値と単位の羅列はどうでしょうか。
単位の羅列については3か所確認しましたが、三者三様の結果が得られました。このため、長くなりますが、すべて見ていきましょう。
まず、JP7331082B2です。
原文は
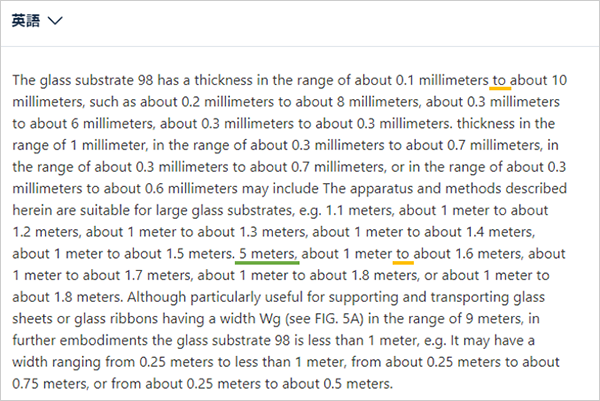
翻訳文は
こちらもJP7331082B2です。
原文は

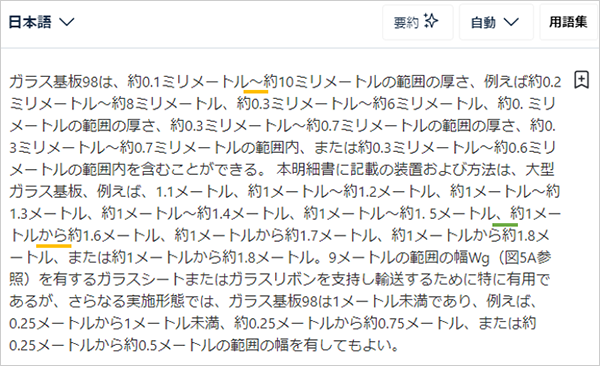
日本語は
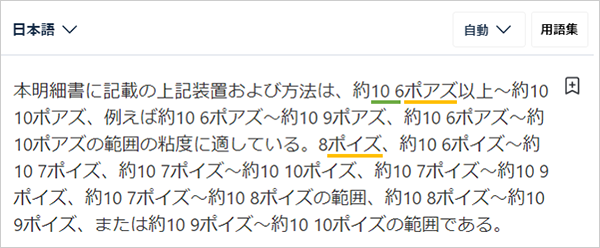
今度は数値と数値の間の「to」は「~」に統一されていますが、単位「poise」が「ポイズ」と「ポアズ」で揺れています(初出箇所に橙線)。どちらでも誤りではありませんが、一つの文書の中ではどちらかに統一してほしいものです。また、これは原文をDeepLに入力したときに既にこの形になってしまっているのですが、「10 6(緑線)」などは「106」と表記を修正する必要があります。
最後に、WO2018089851A2です。
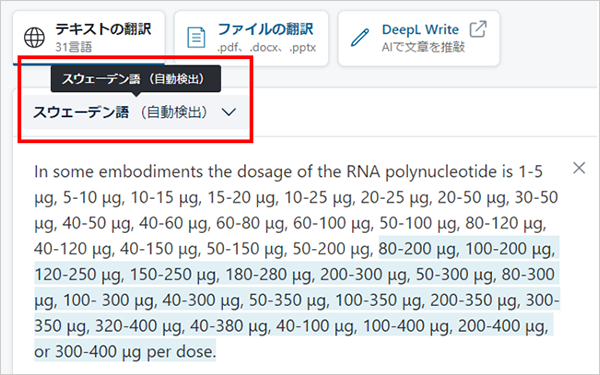
まず、単純に文をコピーして貼ったところ、なぜかスウェーデン語扱いされました。

この場合は、自動検出になっている部分(赤い四角で囲った部分)をクリックして
英語に変更すると
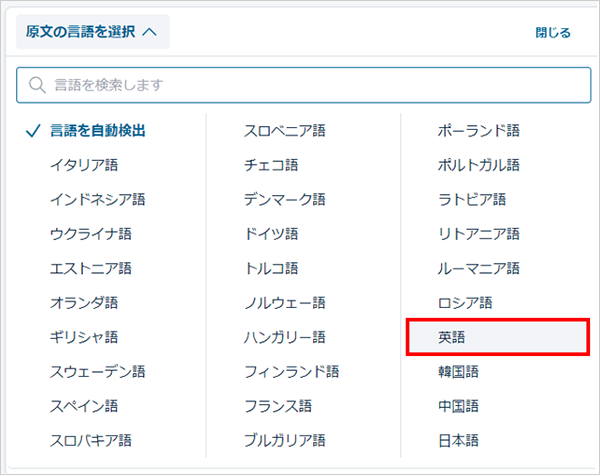
英語と認識され、
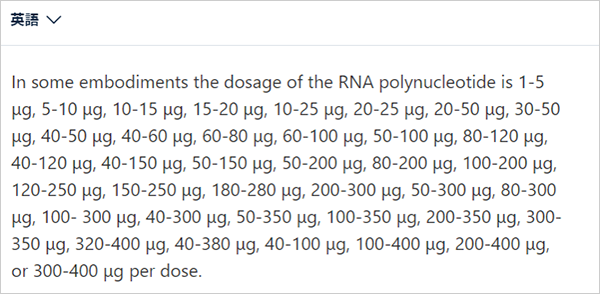
日本語訳が出てきます。

また、今回の場合は、原文を2回繰り返して入力すると、なぜか英語として認識され、日本語訳が作成されました。
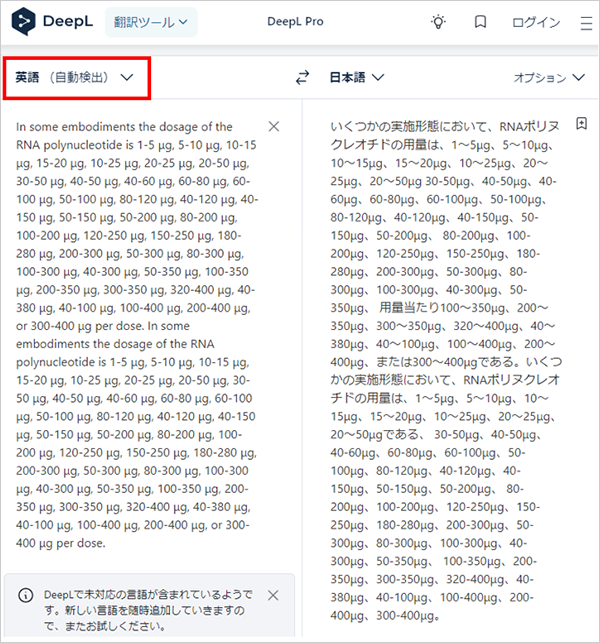
すべての場合において有効かは不明ですが、こういった解決策もあると知っておいて損はないでしょう。
さて、内容の確認に移ります。
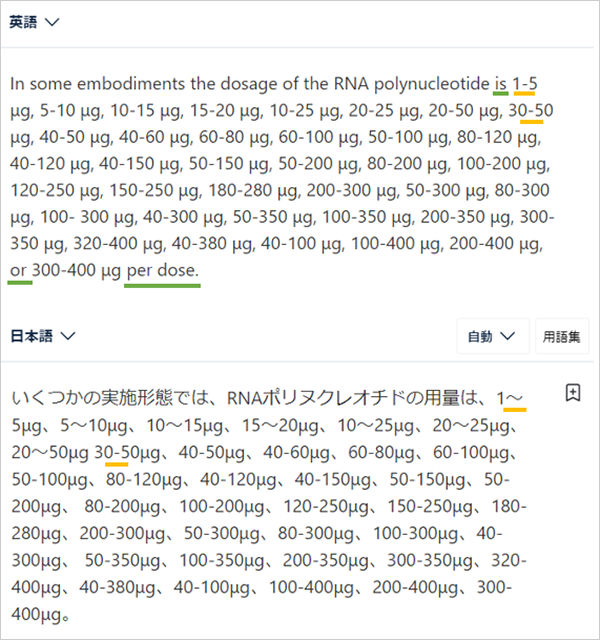
「-」が日本語では「~」と「-」で揺れています(初出箇所に橙線)。また、「is」と「or」と「per dose」が訳されていません(緑線)。これに関しては、2回連続で英語を入力した際に出てきた日本語で面白い現象が起きていました。
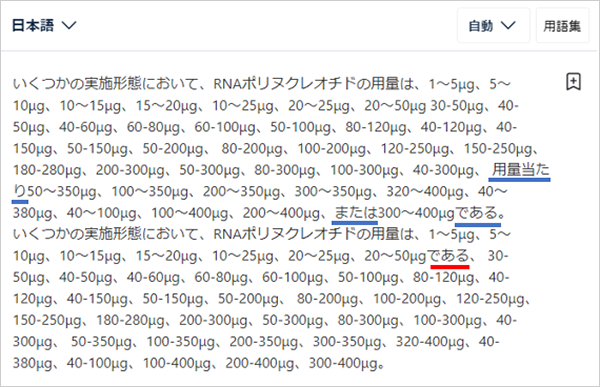
原文を2回繰り返して入力した場合、1回目の訳には「用量当たり」と「または」と「である」が訳出されています(青線)。また、2回目の訳にも「である」が訳出されています(赤線)。位置はともかく訳出されています。正しい訳文を得たいときには同じ文を複数回入力するのも有効なのかもしれません。とはいえ、数字と単位の羅列の場合、
- 数値と数値の間の「to」の訳が揺れる。
- 数値の訳が抜ける。
- 単位の読みが複数ある場合、訳が揺れる。
- 上付きは再現されない。
- 文の訳が抜ける。
等の欠点があり、これを補うために複数回入力をしたとしても、
- いくつかの訳の中から正しいものを選ばなければならない。
- 何回目に正しい文が出てくるかわからない。
- そもそも正しい訳が出てくる保証はない。
という厳しい状況です。以上より、数値と単位に関しては原文をコピーアンドペーストし、Wordでしたら一括置換で日本語訳の完成品に近づけていくのが一番早いかはわかりませんが、確実な気がします。
まとめ
アインシュタインのいう第四次世界大戦の世にでもならない限り、我々は機械翻訳と共に生きていくことになるでしょう。だとしたら、仕事で使ってはいけないことになっている方々も、プライベートでいじってみて、どのように用いればいいのか、どのような訳が作成される傾向があるのか、などを知っておくのは有益なのではないかと思います。今回触ってみて、まず、原語の知識がなくても文をボックスに放り込めば正しい訳文を作ってくれる魔法のツールではないことがはっきりしました。すなわち、翻訳の不備が確率的に(不規則に、予測不可能な形で)生じているのです。これを適切な訳文に仕上げるには、原文と一字一句突き合わせて、かつ文脈レベルでもくまなく検証をして、もれなくチェックを行った上で、不適切な部分をすべて検出して、それに対して必要な修正をすべておこなうことが必要不可欠となります。結局のところ、機械翻訳の出力文を仕上げるには、翻訳対象の内容に対しても言語に対してもそのための十分な知識が求められます。知識がなければ出てきた文が正しいか否か判断できませんからね。その上で、以下:
- 一見完璧に訳されたかに見える文章に潜む訳抜けを見つけ出す注意力
- 自分が訳出させたい文書の形式
- 単語が正確に訳されているか見抜く能力
- 注意力が足りない場合は文書全体を何回確認することになっても根性でそれに耐えること
- 同一の文が同一に訳されているかの確認
- 決まり文句のような、翻訳者ならだれでも訳せるような部分も訳抜けする可能性に常に気を配ること
- 原文で単語が行をまたいでいる箇所は、それに対応する日本語の単語が正しく表記されているかの確認
- 専門的な単語の訳の正否に対する判断
を完璧にこなせるのであれば、機械翻訳は、部分は選びますが、使える場面もあるのではないかと感じました。特に、専門用語の羅列部分は、うまくいけば自分で大半を入力しなくても済むことになりますし。使えない部分のみをクローズアップして「だめだ」と結論付け、一切触らないのはこれから先の時代の流れを考えると得策ではないでしょう。また、機械翻訳の取り扱いに関しては一般社団法人アジア太平洋機械翻訳協会が『MTユーザーガイド ― 機械翻訳で失敗しないための手引き ―』を公開しています。本格的に使ってみようと思った方は、上に挙げた初心者の発見だけではなく、こちらを参考にすることを強くお勧めします。以下のアドレスをクリックして取得してください。
[6]https://aamt.info/wp-content/uploads/2022/09/MT_userguide_v1-1.pdf
ストレートに翻訳には使わないが、何らかの形で機械翻訳と接点を持ちたい、という方には、例えば以下のような使用法が考えられるかと思います。
1.自分の思考方法では考えつかない訳の模索
ChatGPTと共に小説を作っているという方がいらっしゃいますが、考え方はそれに似ていると思います。プロットや自分がこれから描く世界の知識をすべて持っていること、つまり翻訳する文書の分野と言語についての十分な知識があることを前提に、自分には思い浮かばない表現、よりしっくりくる表現を機械翻訳を使って求める感じですね。ChatGPTの場合は、文章を作るのに質問を考え、入力しなければなりませんが、機械翻訳ならば原文となる外国語の文章があればすぐにできます。ただし、上で掲げた注意点は結局のところついて回りますので、すべての文について機械翻訳を用いるのではなく、自分の表現力ではこの文章の凄さが表せない、などの煮詰まった時に物の見方を変えるヒントをくれる最終手段と捉えるとよいかもしれません。
2.急ぎで読まなければならない文書の大意を摑む
文法が多少おかしくても、抜けや過剰部分があってもいい、大体のところを素早く知りたいのだ、というときに用いるのもよいかもしれません。ただ、特許の明細書や学術論文など「今までなかった」事象や「これまでの常識から外れた」事象を扱うものについては、一番大事なところに限って訳が合っているのかこれまでの常識から推し量れず、結局原文を読む羽目に陥り時間をロスすることになりやすいかと思います。納品書のような、これまでの常識から大きく内容が逸れることがないものを選んで用いるとよいかもしれません。
最後に、一番大事な注意点ですが、工夫を重ねれば使えそうでも、訳文を受け取るお客様が「機械翻訳NG」の場合は用いることができませんので、ご注意ください。
サン・フレアは専門的な翻訳を得意としている会社ですので、ぜひご相談いただければと思います。
また、翻訳者として当社にご協力いただける方がいらっしゃいましたら、当社サイトよりご応募いただければ幸いです。
ここまで閲読ありがとうございました。
引用文献
- https://phrase.com/ja/blog/posts/machine-translation/
- https://mx.wovn.io/blog/0003
- https://phrase.com/ja/blog/posts/machine-translation/
- https://www.science.co.jp/nmt/blog/33792/
- https://www.sunflare.com/en/service/
- https://aamt.info/wp-content/uploads/2022/09/MT_userguide_v1-1.pdf
この記事を書いた人

宇佐山
特許関連の翻訳の化学部門で、訳文のチェックを担当しています。
獣医師免許を持っていますが、
学位記を見るまで自分は農学士だと信じて疑いませんでした。