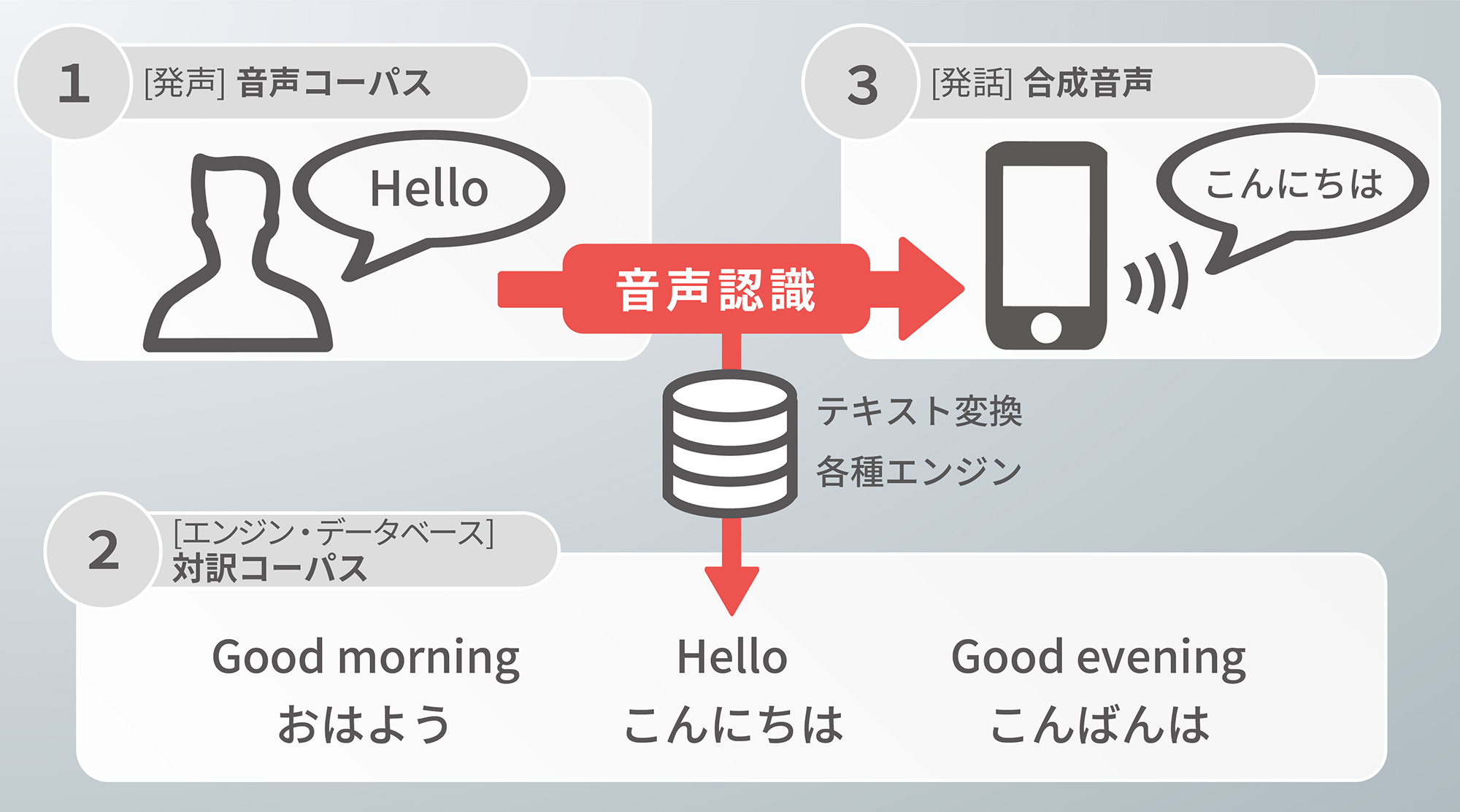
ライフスタイルの変化により、音声認識技術がより身近なものとなりました。音声認識技術がより一層注目される中、サン・フレアは、ローカリゼーションベンダーとしての長年の実績や、世界に拡がる約5,000名のネイティブリソースを基に、音声認識技術を使用されているお客様のサービスをサポートいたします。

音声認識で必要となる大量の音声データを学習させることで、認識精度を上げます。
その元となる音声の収録と対応するテキスト作成を行い、お客様ご希望のデータ形式にてご納品いたします。

データベースにテキストコーパスを読み込ませ、精度を上げるために大量のコーパスを多言語翻訳いたします。特定のシーンに合わせて、会話文の用例を作成することも可能です。

合成音声など、より人間に近い発話を実現するためにチューニングいたします。
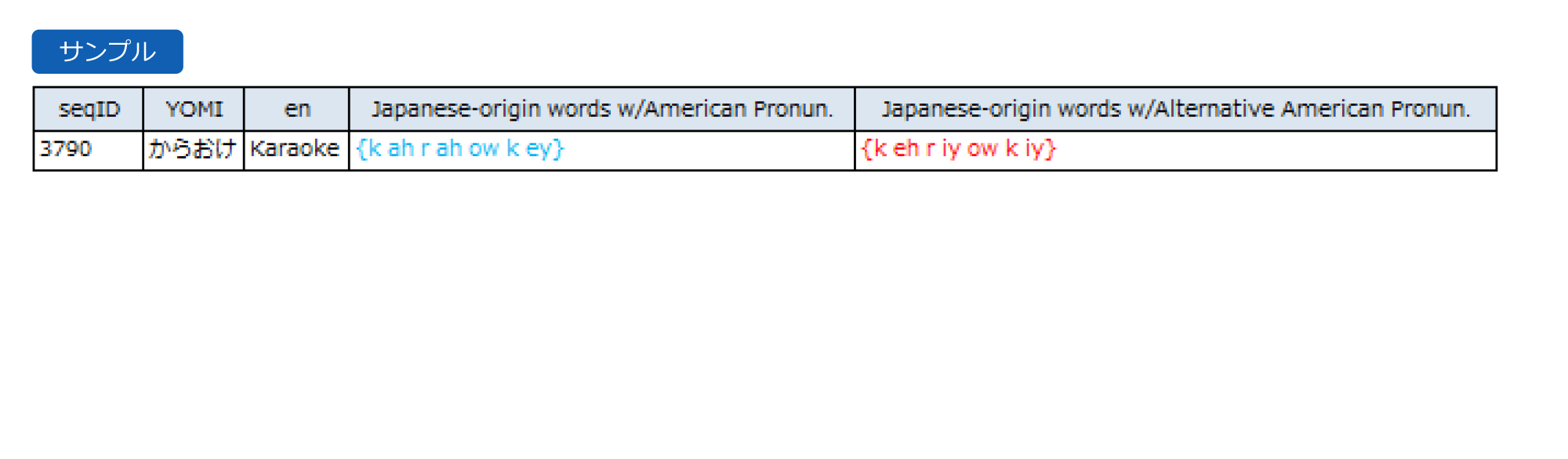
・CMU発音付与サービス
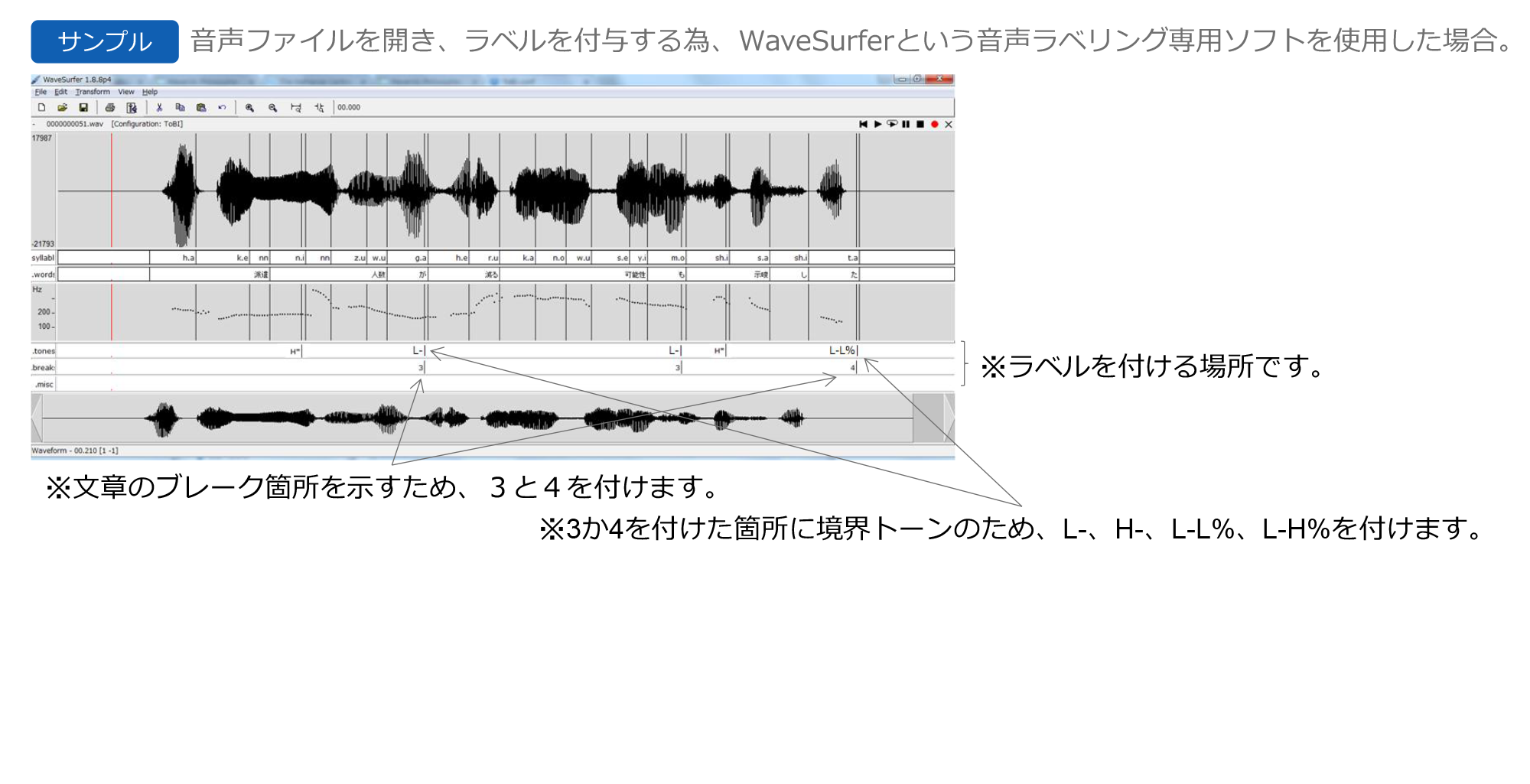
・音声韻律ラベリングサービス
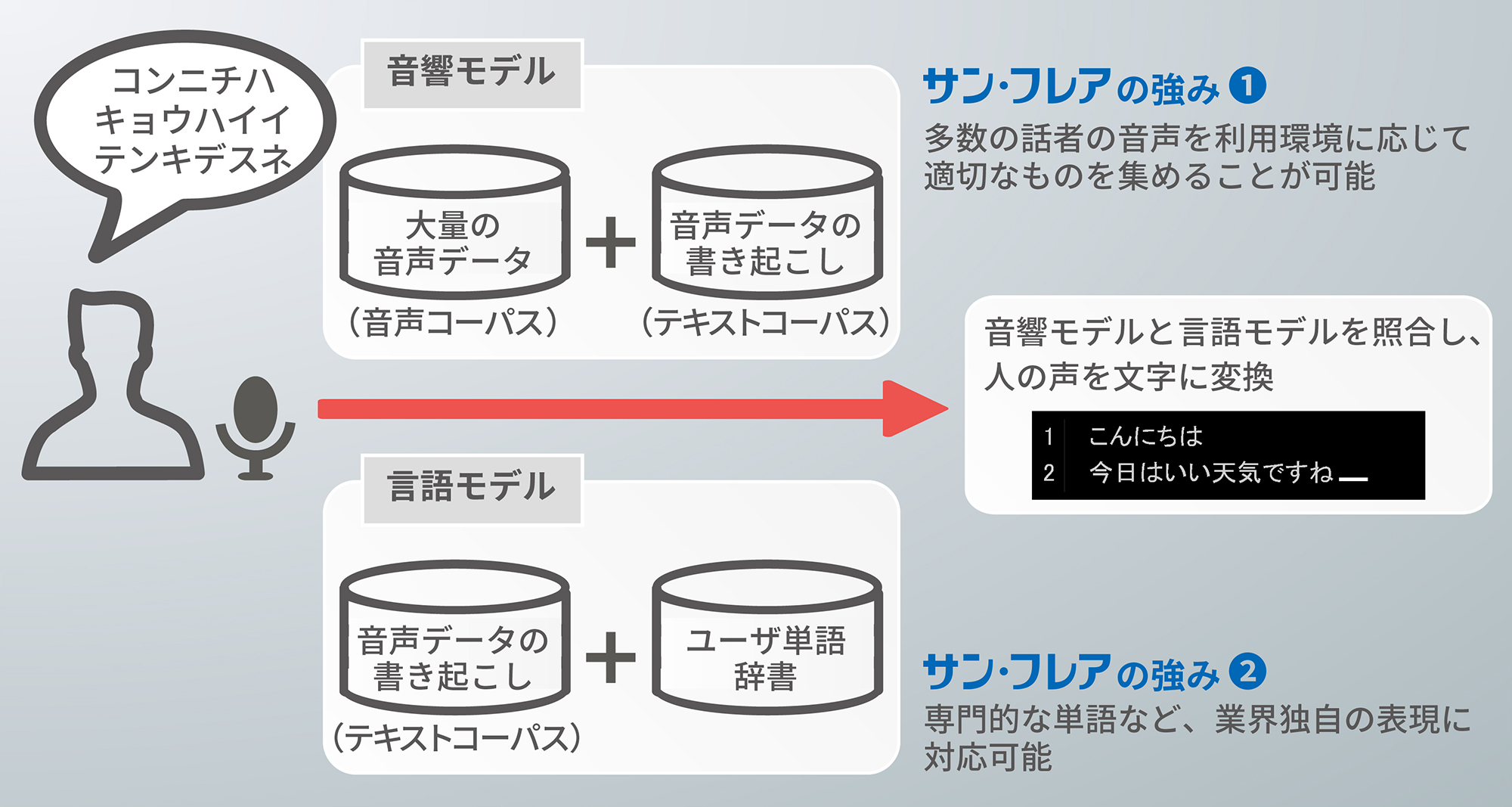
音声認識技術のベースとなるデータは「音響モデル」と「言語モデル」があります。
音声を正しく認識させるためには、これらの元となる「大量の音声データ(音声コーパス)」「音声データの書き起こし(テキストコーパス)」「ユーザ単語辞書」の充実がカギとなります。
サン・フレアの音声認識サポートソリューションでは、このデータ作成においてお客様をサポートいたします。
1. 音声コーパス収録ソリューション
参考事例 音声認識の精度を上げるために、ネイティブが発声した様々なバリエーションの音声データを納品しました。
例:男女 15~60歳の発声データを収集
日本語631人/韓国語645人/インドネシア語3,309人/タイ語4,313人/ミャンマー語3,494人/ベトナム語1,046人 など
2. 対訳コーパス翻訳ソリューション
3. 合成音声チューニングソリューション
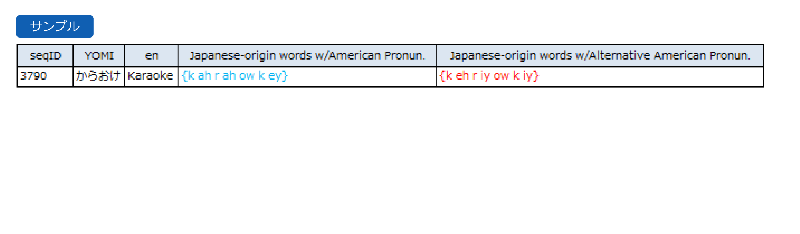
参考事例 CMU発音付与サービス
 クリックで拡大
クリックで拡大
参考事例 音声韻律ラベリングサービス
日本語の音声ファイル及びテキスト文に「韻律情報のラベル」を付け、お客様の人工ニューラルネットワークで認識トレーニングにご利用されました。
 クリックで拡大
クリックで拡大
 クリックで拡大
クリックで拡大